记录在写 goroutine 代码时的常见错误,也会根据其他资料整理一下 goroutine 的一些底层原理。
不要通过共享内存来通信,而是通过通信来实现内存共享
(Do not communicate by sharing memory; instead, share memory by communicating)
goroutine 调度器
一个 go 程序中的 goroutine 需要竞争 cpu 中的操作系统线程资源。goroutine 的调度模型也经过了不断的迭代与衍化。
G-M 模型
G-M 模型是最初的调度器模型,其工作就是将 G 调度到 M 上去运行。为了更好地控制程序中活跃的 M 的数量,调度器引入了 GOMAXPROCS 变量来表示 Go 调度器可见的“处理器”的最大数量。
GM 模型的缺陷:
- 单一全局互斥锁 (Sched.Lock) 和集中状态存储的存在,导致所有 Goroutine 相关操作,比如创建、重新调度等,都要上锁;
- Goroutine 传递问题:M 经常在 M 之间传递“可运行”的 Goroutine,这导致调度延迟增大,也增加了额外的性能损耗;
- 每个 M 都做内存缓存,导致内存占用过高,数据局部性较差;
- 由于系统调用(syscall)而形成的频繁的工作线程阻塞和解除阻塞,导致额外的性能损耗。
G-P-M 模型
GPM 模型向 G-M 模型中增加了一个 P,让 Go 调度器具有很好的伸缩性。
P 是一个“逻辑 Proccessor”,每个 G(Goroutine)要想真正运行起来,首先需要被分配一个 P,也就是进入到 P 的本地运行队列(local runq)中。对于 G 来说,P 就是运行它的“CPU”,可以说:在 G 的眼里只有 P。但从 Go 调度器的视角来看,真正的“CPU”是 M,只有将 P 和 M 绑定,才能让 P 的 runq 中的 G 真正运行起来。
- G: 代表 Goroutine,存储了 Goroutine 的执行栈信息、Goroutine 状态以及 Goroutine 的任务函数等,而且 G 对象是可以重用的;
- P: 代表逻辑 processor,P 的数量决定了系统内最大可并行的 G 的数量,P 的最大作用还是其拥有的各种 G 对象队列、链表、一些缓存和状态;
- M: M 代表着真正的执行计算资源。在绑定有效的 P 后,进入一个调度循环,而调度循环的机制大致是从 P 的本地运行队列以及全局队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。
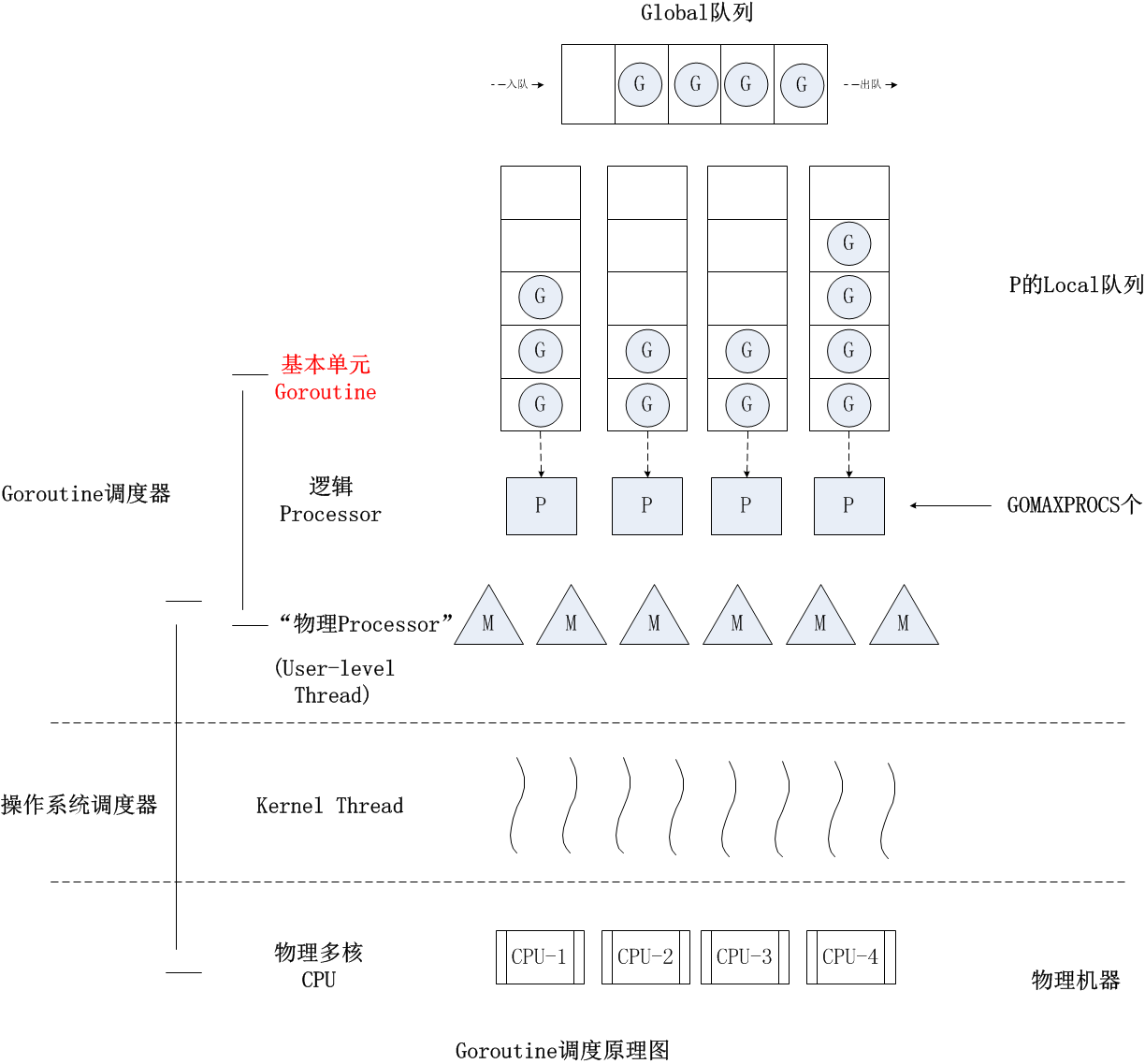
为防止出现 goroutine 饿死情况,调度器实现了基于协作的抢占式调度。Go 编译器在每个函数或方法的入口处加上了一段额外的代码 (runtime.morestack_noctxt),让运行时有机会在这段代码中检查是否需要执行抢占调度。如果一个 G 任务运行 10ms,sysmon 就会认为它的运行时间太久而发出抢占式调度的请求。一旦 G 的抢占标志位被设为 true,那么等到这个 G 下一次调用函数或方法时,运行时就可以将 G 抢占并移出运行状态,放入队列中,等待下一次被调度。
channel 阻塞或网络 I/O 情况下的调度。
如果 G 被阻塞在某个 channel 操作或网络 I/O 操作上时,G 会被放置到某个等待(wait)队列中,而 M 会尝试运行 P 的下一个可运行的 G。如果这个时候 P 没有可运行的 G 供 M 运行,那么 M 将解绑 P,并进入挂起状态。当 I/O 操作完成或 channel 操作完成,在等待队列中的 G 会被唤醒,标记为可运行(runnable),并被放入到某 P 的队列中,绑定一个 M 后继续执行。
系统调用阻塞情况下的调度。
如果 G 被阻塞在某个系统调用(system call)上,那么不光 G 会阻塞,执行这个 G 的 M 也会解绑 P,与 G 一起进入挂起状态。如果此时有空闲的 M,那么 P 就会和它绑定,并继续执行其他 G;如果没有空闲的 M,但仍然有其他 G 要去执行,那么 Go 运行时就会创建一个新 M(线程)。当系统调用返回后,阻塞在这个系统调用上的 G 会尝试获取一个可用的 P,如果没有可用的 P,那么 G 会被标记为 runnable,之前的那个挂起的 M 将再次进入挂起状态。
goroutine
常见错误
1
2
3
4
5
6
7
8
9
|
func Serve(queue chan *Request) {
for req := range queue {
sem <- 1
go func() {
process(req) // 这儿有Bug,解释见下。
<-sem
}()
}
}
|
for 循环中变量在 goroutine 中进行了共享, 正确方式应该将 req 作为参数传入协程。
1
2
3
4
5
6
7
8
9
|
func Serve(queue chan *Request) {
for req := range queue {
sem <- 1
go func(req *Request) {
process(req)
<-sem
}(req)
}
}
|
退出 goroutine
WaitGroup 需要保证所有 Add 在 Wait 之前,否则会出现死锁。- 最好不重用
WaitGroup,因为 WaitGroup 会被复用,可能会出现 WaitGroup 重用的情况,导致 Wait 无法正常工作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 使用 channel 退出 goroutine
done := make(chan struct{})
go func() {
defer close(done)
// ...
}()
// To wait for the goroutine to finish:
<-done
// 使用 waitgroup 等待多个 goroutine 退出
var wg sync.WaitGroup
for i := 0; i < N; i++ {
wg.Add(1)
go func() {
defer wg.Done()
// ...
}()
}
// To wait for all to finish:
wg.Wait()
|
sync.Once
- 用于资源的延迟初始化,只执行一次。
在延迟初始化中若不进行资源加锁,则会出现资源重复初始化的情况,并且并发不安全。
使用 sync.Once.Do(func) 可以保证资源只初始化一次,且并发安全。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 值是3.0或者0.0的一个数据结构
var threeOnce struct {
sync.Once
v *Float
}
// 返回此数据结构的值,如果还没有初始化为3.0,则初始化
func three() *Float {
threeOnce.Do(func() { // 使用Once初始化
threeOnce.v = NewFloat(3.0)
})
return threeOnce.v
} var addr = "baidu.com"
var conn net.Conn
var err error
once.Do(func() {
conn, err = net.Dial("tcp", addr)
})
|
Once 常见错误:
- 在 Do 方法中重复调用 Once.Do 方法,会导致死锁。
- 若在 Do 方法中初始化失败,若后续使用该资源前未进行检查,则可能会导致 panic,该错误可是自定义 Once 原语来解决。如下案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// 一个功能更加强大的Once
type Once struct {
m sync.Mutex
done uint32
}
// 传入的函数f有返回值error,如果初始化失败,需要返回失败的error
// Do方法会把这个error返回给调用者
func (o *Once) Do(f func() error) error {
if atomic.LoadUint32(&o.done) == 1 { //fast path
return nil
}
return o.slowDo(f)
}
// 如果还没有初始化
func (o *Once) slowDo(f func() error) error {
o.m.Lock()
defer o.m.Unlock()
var err error
if o.done == 0 { // 双检查,还没有初始化
err = f()
if err == nil { // 初始化成功才将标记置为已初始化
atomic.StoreUint32(&o.done, 1)
}
}
return err
}
|
Context
- 上下文信息传递 (request-scoped),比如处理 http 请求、在请求处理链路上传递信息;
- 控制子 goroutine 的运行;
- 超时控制的方法调用;
- 可以取消的方法调用。
使用规范
- 一般函数使用 Context 的时候,会把这个参数放在第一个参数的位置。
- 从来不把 nil 当做 Context 类型的参数值,可以使用 context.Background() 创建一个空的上下文对象,也不要使用 nil。
- Context 只用来临时做函数之间的上下文透传,不能持久化 Context 或者把 Context 长久保存。把 Context 持久化到数据库、本地文件或者全局变量、缓存中都是错误的用法。
- key 的类型不应该是字符串类型或者其它内建类型,否则容易在包之间使用 Context 时候产生冲突。使用 WithValue 时,key 的类型应该是自己定义的类型。常常使用 struct{}作为底层类型定义 key 的类型。对于 exported key 的静态类型,常常是接口或者指针。这样可以尽量减少内存分配。
- Context 的 Value 方法应该只用于传递请求域的数据,不要用于传递可选参数。可选参数应该使用函数的参数传递。
context.WithValue
基于父 context 生成新的 context,新的 context 包含了父 context 的所有信息,同时还包含了新添加的 key-value 信息。
1
2
|
ctx = context.TODO()
ctx = context.WithValue(ctx, "key1", "0001")
|
sync.Pool
用于重用与预分配,优化相同的临时对象不断被创建与销毁的性能问题。
- 线程安全,多个 goroutine 可以并发调用。
- 使用
sync.Pool 做 buffer 池可能导致内存泄露,需要丢弃过大的 buffer。
channel
channel 作为 go 语言的一等公民,我们可以像使用普通变量那样使用 channel,比如,定义 channel 类型变量、给 channel 变量赋值、将 channel 作为参数传递给函数 / 方法、将 channel 作为返回值从函数 / 方法中返回,甚至将 channel 发送到其他 channel 中。这就大大简化了 channel 原语的使用,提升了开发者在做并发设计和实现时的体验。
创建 channel
- 和切片、结构体、map 等一样,channel 也是一种复合数据类型。也就是说,我们在声明一个 channel 类型变量时,必须给出其具体的元素类型。
- 如果 channel 类型变量在声明时没有被赋予初值,那么它的默认值为 nil。
- 为 channel 类型变量赋初值的唯一方法就是使用 make
1
2
3
4
5
6
7
8
9
10
11
|
var ch chan int // 初值为 nil
ch1 := make(chan int) // 无缓冲 channel,并赋初值
ch2 := make(chan int, 5) // 带缓冲 channel
ch1 := make(chan<- int, 1) // 只发送channel类型(只能向该channel中发送)
ch2 := make(<-chan int, 1) // 只接收channel类型(只能从该channel中接收)
-----------------------------------------------
<-ch1 // invalid operation: <-ch1 (receive from send-only type chan<- int)
ch2 <- 13 // invalid operation: ch2 <- 13 (send to receive-only type <-chan int)
|
接收与发送
1
2
3
4
5
6
|
ch1 <- 13 // 将整型字面值13发送到无缓冲channel类型变量ch1中
n := <- ch1 // 从无缓冲channel类型变量ch1中接收一个整型值存储到整型变量n中
ch2 <- 17 // 将整型字面值17发送到带缓冲channel类型变量ch2中
m := <- ch2 // 从带缓冲channel类型变量ch2中接收一个整型值存储到整型变量m中
x, sendBeforeClosed := <- ch1 // 第一个返回值是 ch1 中的变量值, 第二个参数用于判断是否是在该 channel 关闭前发送(关闭前发送返回 true)。
|
只发送与只接收类型
通常只发送 channel 类型和只接收 channel 类型,会被用作函数的参数类型或返回值,用于限制对 channel 内的操作,或者是明确可对 channel 进行的操作的类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
func produce(ch chan<- int) {
for i := 0; i < 10; i++ {
ch <- i + 1
time.Sleep(time.Second)
}
close(ch)
}
func consume(ch <-chan int) {
for n := range ch {
println(n)
}
}
func main() {
ch := make(chan int, 5)
var wg sync.WaitGroup
wg.Add(2)
go func() {
produce(ch)
wg.Done()
}()
go func() {
consume(ch)
wg.Done()
}()
wg.Wait()
}
|
无缓冲 channel
- 无缓冲 channel 的读写不能放在同一个 goroutine 中;
- 不要通过共享内存来通信,而是通过通信来共享内存;
- 具有同步性;
- 当 ch 为无缓冲 channel 时,len(ch) 总是返回 0;
由于无缓冲 channel 的运行时层实现不带有缓冲区,所以 Goroutine 对无缓冲 channel 的接收和发送操作是同步的。也就是说,对同一个无缓冲 channel,只有对它进行接收操作的 Goroutine 和对它进行发送操作的 Goroutine 都存在的情况下,通信才能得以进行,否则单方面的操作会让对应的 Goroutine 陷入挂起状态。
用作信号传递
1 对 1 信号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
type signal struct{}
func worker() {
println("worker is working...")
time.Sleep(1 * time.Second)
}
func spawn(f func()) <-chan signal {
c := make(chan signal)
go func() {
println("worker start to work...")
f()
c <- signal{}
}()
return c
}
func main() {
println("start a worker...")
c := spawn(worker)
<-c
fmt.Println("worker work done!")
}
|
这个信号专门用作通知 main goroutine。main goroutine 在调用 spawn 函数后一直阻塞在对这个“通知信号”的接收动作上。
1 对 n 信号传递
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
func worker(i int) {
fmt.Printf("worker %d: is working...\n", i)
time.Sleep(1 * time.Second)
fmt.Printf("worker %d: works done\n", i)
}
type signal struct{}
func spawnGroup(f func(i int), num int, groupSignal <-chan signal) <-chan signal {
c := make(chan signal)
var wg sync.WaitGroup
for i := 0; i < num; i++ {
wg.Add(1)
go func(i int) {
<-groupSignal
fmt.Printf("worker %d: start to work...\n", i)
f(i)
wg.Done()
}(i + 1)
}
go func() {
wg.Wait()
c <- signal{}
}()
return c
}
func main() {
fmt.Println("start a group of workers...")
groupSignal := make(chan signal)
c := spawnGroup(worker, 5, groupSignal)
time.Sleep(5 * time.Second)
fmt.Println("the group of workers start to work...")
close(groupSignal)
<-c
fmt.Println("the group of workers work done!")
}
---------------------------------------------
start a group of workers...
the group of workers start to work...
worker 1: start to work...
worker 1: is working...
worker 2: start to work...
worker 2: is working...
worker 4: start to work...
worker 4: is working...
worker 5: start to work...
worker 5: is working...
worker 3: start to work...
worker 3: is working...
worker 3: works done
worker 5: works done
worker 2: works done
worker 4: works done
worker 1: works done
the group of workers work done!
|
main goroutine 创建了一组 5 个 worker goroutine,这些 Goroutine 启动后会阻塞在名为 groupSignal 的无缓冲 channel 上。main goroutine 通过close(groupSignal)向所有 worker goroutine 广播“开始工作”的信号,收到 groupSignal 后,所有 worker goroutine 会“同时”开始工作。
关闭一个无缓冲 channel 会让所有阻塞在这个 channel 上的接收操作返回,从而实现了一种 1 对 n 的“广播”机制。
替代锁机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
----------传统 共享内存 + 互斥锁 方法-------------
/*
使用了一个带有互斥锁保护的全局变量作为计数器,所有要操作计数器的 Goroutine 共享这个全局变量,并在互斥锁的同步下对计数器进行自增操作。
*/
type counter struct {
sync.Mutex
i int
}
var cter counter
func Increase() int {
cter.Lock()
defer cter.Unlock()
cter.i++
return cter.i
}
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
v := Increase()
fmt.Printf("goroutine-%d: current counter value is %d\n", i, v)
wg.Done()
}(i)
}
wg.Wait()
}
------------channel 实现--------------
type counter struct {
c chan int
i int
}
func NewCounter() *counter {
cter := &counter{
c: make(chan int),
}
go func() {
for {
cter.i++
cter.c <- cter.i
}
}()
return cter
}
func (cter *counter) Increase() int {
return <-cter.c
}
func main() {
cter := NewCounter()
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
v := cter.Increase()
fmt.Printf("goroutine-%d: current counter value is %d\n", i, v)
wg.Done()
}(i)
}
wg.Wait()
}
|
将计数器操作全部交给一个独立的 Goroutine 去处理,并通过无缓冲 channel 的同步阻塞特性,实现了计数器的控制。这样其他 Goroutine 通过 Increase 函数试图增加计数器值的动作,实质上就转化为了一次无缓冲 channel 的接收动作。这种设计符合 go 的理念 不要通过共享内存来通信,而是通过通信来共享内存
有缓冲 channel
- 异步性;
- 无论是 1 收 1 发还是多收多发,带缓冲 channel 的收发性能都要好于无缓冲 channel;
- 对于带缓冲 channel 而言,发送与接收的 Goroutine 数量越多,收发性能会有所下降;
- 对于带缓冲 channel 而言,选择适当容量会在一定程度上提升收发性能;
- 当 ch 为带缓冲 channel 时,len(ch) 返回当前 channel ch 中尚未被读取的元素个数。
和无缓冲 channel 相反,带缓冲 channel 的运行时层实现带有缓冲区,因此,对带缓冲 channel 的发送操作在缓冲区未满、接收操作在缓冲区非空的情况下是异步的(发送或接收不需要阻塞等待)。对一个带缓冲 channel 来说,在缓冲区未满的情况下,对它进行发送操作的 Goroutine 并不会阻塞挂起;在缓冲区有数据的情况下,对它进行接收操作的 Goroutine 也不会阻塞挂起。
注意
不要使用 len 函数来实现带缓冲 channel 的“判满”、“判有”和“判空”逻辑。
channel 原语用于多个 Goroutine 间的通信,一旦多个 Goroutine 共同对 channel 进行收发操作,len(channel) 就会在多个 Goroutine 间形成“竞态”。单纯地依靠 len(channel) 来判断 channel 中元素状态,是不能保证在后续对 channel 的收发时 channel 状态是不变的。
为了不阻塞在 channel 上,常见的方法是将“判空与读取”放在一个“事务”中,将“判满与写入”放在一个“事务”中,而这类“事务”我们可以通过 select 实现。
如下代码实现:
由于用到了 select 原语的 default 分支语义,当 channel 空的时候,tryRecv 不会阻塞;当 channel 满的时候,trySend 也不会阻塞。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
func producer(c chan<- int) {
var i int = 1
for {
time.Sleep(2 * time.Second)
ok := trySend(c, i)
if ok {
fmt.Printf("[producer]: send [%d] to channel\n", i)
i++
continue
}
fmt.Printf("[producer]: try send [%d], but channel is full\n", i)
}
}
func tryRecv(c <-chan int) (int, bool) {
select {
case i := <-c:
return i, true
default:
return 0, false
}
}
func trySend(c chan<- int, i int) bool {
select {
case c <- i:
return true
default:
return false
}
}
func consumer(c <-chan int) {
for {
i, ok := tryRecv(c)
if !ok {
fmt.Println("[consumer]: try to recv from channel, but the channel is empty")
time.Sleep(1 * time.Second)
continue
}
fmt.Printf("[consumer]: recv [%d] from channel\n", i)
if i >= 3 {
fmt.Println("[consumer]: exit")
return
}
}
}
func main() {
var wg sync.WaitGroup
c := make(chan int, 3)
wg.Add(2)
go func() {
producer(c)
wg.Done()
}()
go func() {
consumer(c)
wg.Done()
}()
wg.Wait()
}
|
用于消息队列
channel 的原生特性与我们认知中的消息队列十分相似,包括 Goroutine 安全、有 FIFO(first-in, first out)保证等。和无缓冲 channel 更多用于信号 / 事件管道相比,可自行设置容量、异步收发的带缓冲 channel 更适合被用作为消息队列,并且,带缓冲 channel 在数据收发的性能上要明显好于无缓冲 channel。
用作计数信号量(counting semaphore)
Go 并发设计的一个惯用法,就是将带缓冲 channel 用作计数信号量(counting semaphore)。带缓冲 channel 中的当前数据个数代表的是,当前同时处于活动状态(处理业务)的 Goroutine 的数量,而带缓冲 channel 的容量(capacity),就代表了允许同时处于活动状态的 Goroutine 的最大数量。向带缓冲 channel 的一个发送操作表示获取一个信号量,而从 channel 的一个接收操作则表示释放一个信号量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
var active = make(chan struct{}, 3)
var jobs = make(chan int, 10)
func main() {
go func() {
for i := 0; i < 8; i++ {
jobs <- (i + 1)
}
close(jobs)
}()
var wg sync.WaitGroup
for j := range jobs {
wg.Add(1)
go func(j int) {
active <- struct{}{}
log.Printf("handle job: %d\n", j)
time.Sleep(2 * time.Second)
<-active
wg.Done()
}(j)
}
wg.Wait()
}
----------------
handle job: 1
handle job: 4
handle job: 8
handle job: 5
handle job: 7
handle job: 6
handle job: 3
handle job: 2
|
创建了一组 Goroutine 来处理 job,同一时间允许最多 3 个 Goroutine 处于活动状态。
nil channel
如果一个 channel 类型变量的值为 nil,我们称它为 nil channel。nil channel 有一个特性,那就是对 nil channel 的读写都会发生阻塞。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
func main() {
ch1, ch2 := make(chan int), make(chan int)
go func() {
time.Sleep(time.Second * 5)
ch1 <- 5
close(ch1)
}()
go func() {
time.Sleep(time.Second * 7)
ch2 <- 7
close(ch2)
}()
var ok1, ok2 bool
for {
select {
case x := <-ch1:
ok1 = true
fmt.Println(x)
case x := <-ch2:
ok2 = true
fmt.Println(x)
}
if ok1 && ok2 {
break
}
}
fmt.Println("program end")
}
|
在这个示例中,我们期望程序在接收完 ch1 和 ch2 两个 channel 上的数据后就退出。但实际的运行情况却是这样的:
1
2
3
4
5
6
7
|
5
0
0
0
... ... //循环输出0
7
program end
|
前 5s,select 一直处于阻塞状态;第 5s,ch1 返回一个 5 后被 close,select 语句的case x := <-ch1这个分支被选出执行,程序输出 5,并回到 for 循环并重新 select;由于 ch1 被关闭,从一个已关闭的 channel 接收数据将永远不会被阻塞,于是新一轮 select 又把case x := <-ch1这个分支选出并执行。由于 ch1 处于关闭状态,从这个 channel 获取数据,我们会得到这个 channel 对应类型的零值,这里就是 0。于是程序再次输出 0;程序按这个逻辑循环执行,一直输出 0 值;2s 后,ch2 被写入了一个数值 7。这样在某一轮 select 的过程中,分支case x := <-ch2被选中得以执行,程序输出 7 之后满足退出条件,于是程序终止。
使用 nil channel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
func main() {
ch1, ch2 := make(chan int), make(chan int)
go func() {
time.Sleep(time.Second * 5)
ch1 <- 5
close(ch1)
}()
go func() {
time.Sleep(time.Second * 7)
ch2 <- 7
close(ch2)
}()
for {
select {
case x, ok := <-ch1:
if !ok {
ch1 = nil
} else {
fmt.Println(x)
}
case x, ok := <-ch2:
if !ok {
ch2 = nil
} else {
fmt.Println(x)
}
}
if ch1 == nil && ch2 == nil {
break
}
}
fmt.Println("program end")
}
|
关闭 Channel
- 关闭惯例:发送端负责关闭 channel;
- 一个已关闭的 channel 仍然可以从该 channel 中接收到 channel 类型的零值。
- channel 一旦没有人引用了,就会被 gc 掉,不关闭也 ok。但是如果有 goroutine 一直在读 channel,那么 channel 一直存在,不会关闭。直到程序退出;
- channel 如果不 close,也不会存在资源泄露的问题。这是因为发送端没有像接受端那样的、可以安全判断 channel 是否被关闭了的方法。同时,一旦向一个已经关闭的 channel 执行发送操作,这个操作就会引发 panic。
1
2
3
4
5
|
n := <- ch // 当ch被关闭后,n将被赋值为ch元素类型的零值
m, ok := <-ch // 当ch被关闭后,m将被赋值为ch元素类型的零值, ok值为false
for v := range ch { // 当ch被关闭后,for range循环结束
... ...
}
|
在判断是否需要主动关闭 channel 时,若发送 channel 小于接收 channel 则需要由发送的 goroutine 主动关闭 channel。
如下情景使用 range 遍历 channel,如果不主动关闭 ch,range 则不会退出 wg.Wait 永远不会达成。发送 goroutine 未主动关闭 channel,接收端持续等待发送端的 ch 而阻塞,导致接受者 goroutine 也不会主动退出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
var ch = make(chan int, 5)
func Producer(id int, delay time.Duration) {
time.Sleep(delay * time.Second)
fmt.Println("produce ", id)
ch <- id
}
func Consumer(id int, delay time.Duration) {
time.Sleep(delay * time.Second)
fmt.Println("consume ", id)
}
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
defer close(ch)
for i := 0; i < 10; i++ {
Producer(i, 1)
}
}()
go func() {
defer wg.Done()
for id := range ch { // 相当于发送小于接收,若发送者不主动关闭会阻塞
Consumer(id, 2)
}
}()
wg.Wait()
}
|
select
- select 中分支的选择是随机的,会从所有准备好的分支中随机选择一个执行。
- 如果 select 中没有 default 分支,并所有分支都未准备就绪则会阻塞。
通过 select,我们可以同时在多个 channel 上进行发送 / 接收操作:
1
2
3
4
5
6
7
8
9
10
11
12
|
select {
case x := <-ch1: // 从channel ch1接收数据
... ...
case y, ok := <-ch2: // 从channel ch2接收数据,并根据ok值判断ch2是否已经关闭
... ...
case ch3 <- z: // 将z值发送到channel ch3中:
... ...
default: // 当上面case中的channel通信均无法实施时,执行该默认分支
}
|
当 select 语句中没有 default 分支,而且所有 case 中的 channel 操作都阻塞了的时候,整个 select 语句都将被阻塞,直到某一个 case 上的 channel 变成可发送,或者某个 case 上的 channel 变成可接收,select 语句才可以继续进行下去。
利用 default 分支避免阻塞
select 语句的 default 分支的语义,就是在其他非 default 分支因通信未就绪,而无法被选择的时候执行的,这就给 default 分支赋予了一种“避免阻塞”的特性。
无论是无缓冲 channel 还是带缓冲 channel,这两个函数都能适用,并且不会阻塞在空 channel 或元素个数已经达到容量的 channel 上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func tryRecv(c <-chan int) (int, bool) {
select {
case i := <-c:
return i, true
default: // channel为空
return 0, false
}
}
func trySend(c chan<- int, i int) bool {
select {
case c <- i:
return true
default: // channel满了
return false
}
}
|
实现超时机制
带超时机制的 select,是 Go 中常见的一种 select 和 channel 的组合用法。通过超时事件,我们既可以避免长期陷入某种操作的等待中,也可以做一些异常处理工作。
1
2
3
4
5
6
7
8
|
func worker() {
select {
case <-c:
// ... do some stuff
case <-time.After(30 *time.Second):
return
}
}
|
注意
要特别注意 timer 使用后的释放,尤其在大量创建 timer 的时候。
要尽量减少在使用 Timer 时给 Go 运行时和 Go 垃圾回收带来的压力,要及时调用 timer 的 Stop 方法回收 Timer 资源。
实现心跳机制
结合 time 包的 Ticker,我们可以实现带有心跳机制的 select。这种机制让我们可以在监听 channel 的同时,执行一些周期性的任务,比如下面这段代码:
1
2
3
4
5
6
7
8
9
10
11
12
|
func worker() {
heartbeat := time.NewTicker(30 * time.Second)
defer heartbeat.Stop()
for {
select {
case <-c:
// ... do some stuff
case <- heartbeat.C:
//... do heartbeat stuff
}
}
}
|
这里我们使用 time.NewTicker,创建了一个 Ticker 类型实例 heartbeat。这个实例包含一个 channel 类型的字段 C,这个字段会按一定时间间隔持续产生事件,就像“心跳”一样。这样 for 循环在 channel c 无数据接收时,会每隔特定时间完成一次迭代,然后回到 for 循环进行下一次迭代。
和 timer 一样,我们在使用完 ticker 之后,也不要忘记调用它的 Stop 方法,避免心跳事件在 ticker 的 channel(上面示例中的 heartbeat.C)中持续产生。
使用反射动态选择 case
chan 的数量不固定,无法在编译期确定,所以无法使用常规的 select 语句,因此可以使用反射机制来实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
func main() {
var ch1 = make(chan int, 10)
var ch2 = make(chan int, 10)
// 创建SelectCase
var cases = createCases(ch1, ch2)
// 执行10次select
for i := 0; i < 10; i++ {
chosen, recv, ok := reflect.Select(cases)
if recv.IsValid() { // recv case
fmt.Println("recv:", cases[chosen].Dir, recv, ok)
} else { // send case
fmt.Println("send:", cases[chosen].Dir, ok)
}
}
}
func createCases(chs ...chan int) []reflect.SelectCase {
var cases []reflect.SelectCase
// 创建recv case
for _, ch := range chs {
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectRecv,
Chan: reflect.ValueOf(ch),
})
}
// 创建send case
for i, ch := range chs {
v := reflect.ValueOf(i)
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectSend,
Chan: reflect.ValueOf(ch),
Send: v,
})
}
return cases
}
|
共享内存方式的同步(sync)
在 Go 中,channel 并发原语也可以用于对数据对象访问的同步,我们可以把 channel 看成是一种高级的同步原语,它自身的实现也是建构在低级同步原语之上的。也正因为如此,channel 自身的性能与低级同步原语相比要略微逊色,开销要更大。
高性能的临界区(critical section)同步
- 通常在需要高性能的临界区(critical section)同步机制的情况下,sync 包提供的低级同步原语更为适合。
- 在不想转移结构体对象所有权,但又要保证结构体内部状态数据的同步访问的场景。如果你的设计中没有转移结构体对象所有权,但又要保证结构体内部状态数据在多个 Goroutine 之间同步访问,那么你可以使用 sync 包提供的低级同步原语来实现,比如最常用的sync.Mutex。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
var cs = 0 // 模拟临界区要保护的数据
var mu sync.Mutex
var c = make(chan struct{}, 1)
func criticalSectionSyncByMutex() {
mu.Lock()
cs++
mu.Unlock()
}
func criticalSectionSyncByChan() {
c <- struct{}{}
cs++
<-c
}
|
互斥锁
sync 包提供了两种用于临界区同步的原语:互斥锁(Mutex)和读写锁(RWMutex)。它们都是零值可用的数据类型,也就是不需要显式初始化就可以使用。
1
2
3
4
|
var mu sync.Mutex
mu.Lock() // 加锁
doSomething()
mu.Unlock() // 解锁
|
一旦某个 Goroutine 调用的 Mutex 执行 Lock 操作成功,它将成功持有这把互斥锁。这个时候,如果有其他 Goroutine 执行 Lock 操作,就会阻塞在这把互斥锁上,直到持有这把锁的 Goroutine 调用 Unlock 释放掉这把锁后,才会抢到这把锁的持有权并进入临界区。
- 尽量减少在锁中的操作。
- 一定要记得调用 Unlock 解锁。
读写锁
底层写优先,多用于读多写少的业务,写锁与 Mutex 的行为十分类似,一旦某 Goroutine 持有写锁,其他 Goroutine 无论是尝试加读锁,还是加写锁,都会被阻塞在写锁上。
但读锁就宽松多了,一旦某个 Goroutine 持有读锁,它不会阻塞其他尝试加读锁的 Goroutine,但加写锁的 Goroutine 依然会被阻塞住。
- 避免重入调用,当活跃的读锁依赖新的读锁时调用写锁,这会导致死锁。
1
2
3
4
5
6
7
|
var rwmu sync.RWMutex
rwmu.RLock() //加读锁
readSomething()
rwmu.RUnlock() //解读锁
rwmu.Lock() //加写锁
changeSomething()
rwmu.Unlock() //解写锁
|
- 并发量较小的情况下,Mutex 性能最好;随着并发量增大,Mutex 的竞争激烈,导致加锁和解锁性能下降;
- RWMutex 的读锁性能并没有随着并发量的增大,而发生较大变化;
- 在并发量较大的情况下,RWMutex 的写锁性能和 Mutex、RWMutex 读锁相比,是最差的,并且随着并发量增大,RWMutex 写锁性能有继续下降趋势。
- 读写锁适合应用在具有一定并发量且读多写少的场合。
不应复制使用过的 Mutex
- 首次使用 Mutex 等 sync 包中定义的结构类型后,不应该再对它们进行复制操作;
- 在使用 sync 包中的类型的时候,我们推荐通过闭包方式,或者是传递类型实例(或包裹该类型的类型实例)的地址(指针)的方式进行;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
func main() {
var wg sync.WaitGroup
i := 0
var mu sync.Mutex // 负责对i的同步访问
wg.Add(1)
// g1
go func(mu1 sync.Mutex) {
mu1.Lock()
i = 10
time.Sleep(10 * time.Second)
fmt.Printf("g1: i = %d\n", i)
mu1.Unlock()
wg.Done()
}(mu)
time.Sleep(time.Second)
mu.Lock()
i = 1
fmt.Printf("g0: i = %d\n", i)
mu.Unlock()
wg.Wait()
}
----------------------
g0: i = 1
g1: i = 1
|
在这个例子中,使用一个 sync.Mutex 类型变量 mu 来同步对整型变量 i 的访问。我们创建一个新 Goroutine:g1,g1 通过函数参数得到 mu 的一份拷贝 mu1,然后 g1 会通过 mu1 来同步对整型变量 i 的访问。第 9 行 g1 对 mu1 的加锁操作,并没能阻塞第 19 行 g0 对 mu 的加锁。于是,g1 刚刚将 i 赋值为 10 后,g0 就又将 i 赋值为 1 了。
一旦 Mutex 类型变量被拷贝,原变量与副本就各自发挥作用,互相没有关联了。甚至,如果拷贝的时机不对,比如在一个 mutex 处于 locked 的状态时对它进行了拷贝,就会对副本进行加锁操作,将导致加锁的 Goroutine 永远阻塞下去。
sync.Cond
sync.Cond 条件变量用来协调想要访问共享资源的那些 goroutine,当共享资源的状态发生变化的时候,它可以用来通知被互斥锁阻塞的 goroutine。条件变量 sync.Cond 用来协调想要访问共享资源的 goroutine。
sync.Cond 经常用在多个 goroutine 等待,一个 goroutine 通知(事件发生)的场景。如果是一个通知,一个等待,使用互斥锁或 channel 就能搞定。
有一个协程在异步地接收数据,剩下的多个协程必须等待这个协程接收完数据,才能读取到正确的数据。在这种情况下,如果单纯使用 chan 或互斥锁,那么只能有一个协程可以等待,并读取到数据,没办法通知其他的协程也读取数据。这个时候,就需要有个全局的变量来标志第一个协程数据是否接受完毕,剩下的协程,反复检查该变量的值,直到满足要求。或者创建多个 channel,每个协程阻塞在一个 channel 上,由接收数据的协程在数据接收完毕后,逐个通知。总之,需要额外的复杂度来完成这件事。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
var done = false
func read(name string, c *sync.Cond) {
c.L.Lock()
for !done {
c.Wait()
}
log.Println(name, "starts reading")
c.L.Unlock()
}
func write(name string, c *sync.Cond) {
log.Println(name, "starts writing")
time.Sleep(time.Second)
c.L.Lock()
done = true
c.L.Unlock()
log.Println(name, "wakes all")
c.Broadcast()
}
func main() {
cond := sync.NewCond(&sync.Mutex{})
go read("reader1", cond)
go read("reader2", cond)
go read("reader3", cond)
write("writer", cond)
time.Sleep(time.Second * 3)
}
|
三个协程调用 Wait() 等待,另一个协程调用 Broadcast() 唤醒所有等待的协程。
- done 即互斥锁需要保护的条件变量。
- read() 调用 Wait() 等待通知,直到 done 为 true。
- write() 接收数据,接收完成后,将 done 置为 true,调用 Broadcast() 通知所有等待的协程。
- write() 中的暂停了 1s,一方面是模拟耗时,另一方面是确保前面的 3 个 read 协程都执行到 Wait(),处于等待状态。main 函数最后暂停了 3s,确保所有操作执行完毕。
优雅的处理 goroutine 中的错误
不要通过共享内存来通信,而是通过通信来实现内存共享(Do not communicate by sharing memory; instead, share memory by communicating)。
使用 channel 传递错误
像我之前写的一个爬取 Github starred 的仓库的脚本,在 goroutine 中使用 channel 传递错误。
github 地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
func getReposGoroutine(username string, maxRepo int) ([]RepoData, error) {
var (
repoCnt int
allRepos []RepoData
ch = make(chan struct{}, 5)
gerrors = make(chan error)
wg sync.WaitGroup
mu sync.Mutex
done = make(chan struct{})
// pageIdx = 1
)
for i := 1; i < maxRepo/30+2; i++ {
ch <- struct{}{}
wg.Add(1)
go func(pageIdx int) {
defer func() {
wg.Done()
<-ch
}()
resp, err := http.Get(fmt.Sprintf("https://api.github.com/users/%s/starred?page=%d&per_page=%d", username, pageIdx, 30))
if err != nil {
gerrors <- err
}
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
gerrors <- err
}
var jsonData []RepoData
if err := json.Unmarshal(body, &jsonData); err != nil {
gerrors <- err
}
mu.Lock()
repoCnt += len(jsonData)
allRepos = append(allRepos, jsonData...)
mu.Unlock()
}(i)
}
go func() {
wg.Wait()
close(done)
}()
select {
case err := <-gerrors:
return nil, err
case <-done:
break
}
return allRepos, nil
}
|
使用 sync/errgroup
- errgroup 包提供了一个同步的 goroutine 管理器,可以同时启动多个 goroutine,等待它们全部结束,或者其中任意一个出错时立即返回。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func main() {
g := new(errgroup.Group)
var urls = []string{
"http://www.golang.org/",
"https://golang2.eddycjy.com/",
"https://eddycjy.com/",
}
for _, url := range urls {
url := url
g.Go(func() error {
resp, err := http.Get(url)
if err == nil {
resp.Body.Close()
}
return err
})
}
if err := g.Wait(); err == nil {
fmt.Println("Successfully fetched all URLs.")
} else {
fmt.Printf("Errors: %+v", err)
}
}
|
 Niku
Niku